A mature retrieval-augmented system is not the clean diagram from the architecture review. It is a base pipeline plus a long tail of deterministic rules: filter the top-1 passage when the reranker margin is below a threshold, drop a passage that matches a known stale-content fingerprint, abstain when the query has these three properties, swap rerank ordering when the retrieval pool is dominated by one source. Each rule was added for a reason. Each rule targets a query class that, on its own, is too small to power an A/B test. Most rules ship without controlled experiments because the alternative (wait long enough to power one) costs more than the rule is worth.
Once you have a hundred such rules in the pipeline, the question stops being "should we add this rule?" and starts being "which of these rules are still earning their keep, and which candidates in the queue are worth promoting?" That question has a name in the literature (off-policy evaluation), and its standard formulation does not survive contact with a production RAG system.
This is the regime Phyvant works in. We run retrieval-augmented back-office automation in production at large enterprises, including at one of the world's largest commodity traders, where the rule pool grows the way mature pipelines grow: by accumulation, faster than any A/B-testing cadence can ratify. Shipping the wrong rule into that environment does not fail loudly; it silently re-routes a subset of work to a worse policy, on the very operators the system exists to make faster. That is the failure mode a regulated workflow cannot absorb: no alarm, no dashboard spike, just a worse answer that surfaces in an audit. The off-policy evaluation procedure has to be cheap enough to run continuously, and structurally honest enough that the ranking it produces holds up to scrutiny.
This post walks through the three obstacles that make this hard, the deployment-time observable we use to pick the right estimator, and the recipe we run on every new substrate.
Why textbook off-policy evaluation breaks
You have a log of N interactions: query, retrieval pipeline output, generator answer, reward signal (thumbs, alias-match against a gold answer, F1 against an extracted reference, whatever your shop uses). You have a candidate rule that would have changed the pipeline's behavior on some subset of those interactions. You want to estimate, without running the rule in production and without re-invoking the language model, what the average reward would have been if the rule had been live during the logging window. Multiply by 500 candidate rules. The estimate has to be cheap, has to be honest about uncertainty, and has to rank rules consistently enough that the rules you promote are actually the good ones.
Three things compound to make this hard.
Importance weighting fails on deterministic logs. The textbook estimator reweights logged rewards by the ratio of the candidate policy to the logging policy:
It requires the logging policy to randomise actions. Production RAG pipelines do not randomise. They are deterministic compositions: for every state. A candidate rule that would have chosen a different action than the logged pipeline gets in the denominator on every record where it differs: the estimator is undefined where it matters and zero everywhere else.
You can fix this by running uniform-stochastic logging on a slice of traffic: randomise actions deliberately so the importance weights are non-zero. We do this, but only for a small budgeted pilot. You cannot afford to randomise across the whole pipeline on real users, and you cannot retroactively make the historical log stochastic.
Replay does not scale. You can sidestep importance weighting by re-invoking the generator under each candidate rule's modified retrieval: produce the counterfactual answer directly. This works. It costs roughly M times N generator calls for M candidate rules over N logged queries. For a 500-rule queue and a non-trivial log, that is a multi-GPU-week bill, every time you re-evaluate the queue. It does not scale to the cadence at which engineers ship rules in production.
The right estimator depends on the deployment. This is the obstacle that is the least visible and the most consequential. The relative quality of two off-policy estimators is not a property of the estimators. It is a property of the deployment.
Across a grid we run internally (twelve open-weights generators in the 1.7B–9B range, three QA-style benchmarks, four sample sizes), the magnitude of one estimator's advantage over another spans +8% to +358% on the same benchmark with identical retrieval atoms, identical rule pool, identical reward function, changing only the language model. Cross-model orderings flip across benchmarks. Cross-estimator orderings flip across sample sizes. Three independent estimator pairs we tested all show the same multiplicative interaction structure, with the LLM-side and benchmark-side effects combining non-additively. The phenomenon is a property of the OPE problem on this substrate, not of any specific estimator. A team that adopts whichever estimator the most recent paper claims best MSE for, and uses it everywhere, will silently mis-rank rules on the model-benchmark combinations where that estimator's advantage flips.
The deployment-time observable
We need a single number, computable from the language model alone, that predicts which estimator will perform better on a given substrate. The number we use is the within-query variance of per-action reward.
Concretely: take a small pilot (on the order of a hundred queries) and run them under uniform-stochastic logging so each candidate retrieval action is exercised. For each pilot query we now have a per-action reward vector. Compute the within-query variance and average over queries:
Operationally, is the answer to "how much does the language model's reward depend on which action the rule chooses?" When is small, the model is producing similar-quality answers regardless of which retrieval action it sees: it is not strongly differentiating actions, and the off-policy estimator's job is structurally easier. When is large, the model is highly action-sensitive: the same query produces wildly different rewards under different actions, and the estimator has to do real work to extract a signal.
Why does this single observable predict which estimator wins? Because both and the gap between estimators are reading the same underlying quantity through different lenses. Both depend on how much the language model's behavior varies with the retrieval action; both vanish exactly when the language model is not differentiating actions. The relationship is structural, not coincidental. Empirically, both quantities track each other tightly across the workload grid; theoretically, they share their underlying matrix and are bounded by each other up to constants that depend only on the rule pool and feature design, not on the LLM. The structural reason and the empirical fit agree.
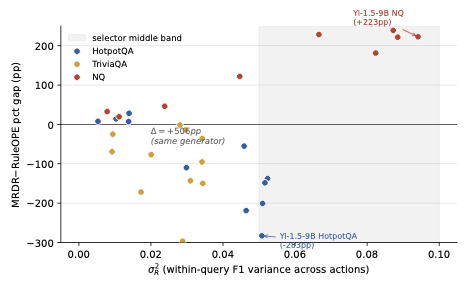
The figure is the picture of what conditional ranking actually looks like on a workload grid. Each dot is one model-benchmark cell. The y-axis is the head-to-head margin between two off-policy estimators in percentage points. The x-axis is . The two clusters are doing different things: low- cells favour the atom-sharing regression by a wide margin; high- cells reverse the sign. Two of the most extreme cells highlighted on the figure share the same language model: the gap between them, more than five hundred percentage points on the same generator, is entirely a benchmark effect, and catches it without ever fitting an estimator.
The recipe
The procedure is straightforward to operate.
Allocate a small budget (roughly a hundred queries) for uniform-stochastic logging. On those queries, the generator runs under each candidate retrieval action so we have the per-action reward matrix. We compute from that matrix. The rest of the rule queue is evaluated against the deterministic log; the pilot is the only randomised piece.
If is below a low threshold (around 0.05 in our setup), we use a doubly-robust estimator that shares parameters across rules through a fixed atom vocabulary: its variance scales with the atom dimension regardless of how many rules are in the queue. If is above a higher threshold (around 0.10 in our setup, though we have not actually observed it in our calibration distribution), we switch to an action-weighted regression that absorbs action-side variance better, accepting a per-rule cost. In the middle band we run a slightly larger pilot: the reading is uncertain in that band and the right move is to break the tie with data rather than with a model.
Both thresholds are calibrated against the released grid; new substrates require a fresh pilot calibration. We do not skip that step.
What we measure
On a pooled audit of fifty-four cells spanning in-grid generators, a different retrieval substrate, and frontier-scale anchors at 14B and 32B, the -thresholded selector picks the right estimator in 40 of 54 cells (74%), against an always-use-the-favored-estimator baseline that gets 33 of 54. Of the seventeen middle-band cells where the prediction is uncertain enough that the always-baseline could be wrong, the procedure rescues seven with no harms. Frontier anchors at 14B and 32B confirm the predicted failure mode at the largest pair gap in the evaluation, around three hundred percentage points.
The phenomenon also reaches the lens itself. On 8 of 36 cells on Natural Questions, the doubly-robust per-rule estimator we use as the instrument falls below its non-compositional baseline at sample size 1200, and the gap deepens at 2400, direct evidence that the conditional ranking is structural to the OPE problem on this substrate, not specific to any one estimator.
Scope
The selector is calibrated for QA-with-retrieval on open-weights generators from 1.7B through 32B, against a small set of estimator families, on rule pools that meet firing-rate and action-coverage conditions we verify per pool. New substrates need a fresh hundred-query pilot: the thresholds do not transport unverified. And it is a tiebreaker: it picks the better of two reasonable estimators on this substrate, not a guarantee that the rule pool is well-designed or the reward signal meaningful.
What this changes about how we ship rules
Two things change once is the deployment-time handle.
The first is that "which off-policy estimator should we use?" stops being a one-time methodology decision and becomes a runtime selection. The answer is allowed to depend on the model, the benchmark, and the sample size we have. When the language model behind the pipeline turns over (a routine event with how fast open-weights generators move), we re-pilot and re-pick. The estimator is part of the configuration, not part of the architecture.
The second is that rule queue size stops being a cost ceiling. Generator-replay cost is paid once on the pilot, fixed independent of how many candidate rules are in the queue. Adding a hundred new candidate rules costs a tabular regression evaluation pass, not a hundred new pilots: the rule pool scales without the bill scaling with it. This is the change that turns rule-driven retrieval engineering into a governed, continuous discipline instead of a one-rule-per-quarter ritual, and it is what lets an enterprise grow the pipeline without losing the audit trail under it.