A production retrieval-augmented system makes one decision over and over: take a query, fuse a few relevance signals into a score, and if that score crosses a threshold, ground the generation in retrieved passages. If it doesn't cross, abstain or escalate. The threshold is the safety valve. Whether the valve does anything useful depends entirely on whether the score it gates is a calibrated probability of relevance.
The standard way teams check that property is marginal Expected Calibration Error: bin queries by predicted score, compare each bin's mean prediction to its empirical hit rate on a held-out set, sum the weighted gap. If the curve hugs the diagonal, the system is calibrated and the threshold is meaningful. Most teams report this number, see it small, and ship.
We've spent enough time inside production retrieval pipelines to be convinced this is the wrong instrument. The mistake is not subtle, the failure mode is structural, and on every workload we evaluate the dashboard a team is monitoring is hiding the problem rather than surfacing it. This post is about what marginal calibration averages out of existence, why a fused score is especially good at hiding it, and what we do instead.
The threshold is a probability claim
When a system thresholds a fused score at 0.7 to decide whether to ground a generation, it is asserting something specific: among queries it answers at this confidence, roughly seventy percent of the time the retrieved passage is genuinely relevant. That's a probability claim, and calibration is the only property that can validate or refute it. If the score is calibrated, the threshold is meaningful and you can reason about hallucination rates downstream of it. If it isn't, the threshold is just a number you tuned on a validation set; whatever guarantees the abstention path looks like it gives, you don't actually have them.
This is why every RAG playbook eventually reaches for calibration. The instinct is right. The instrument is the problem.
Aggregate ECE averages errors that should not be averaged
The standard metric — Expected Calibration Error — is a single weighted average across the whole test set:
This works when your model's errors are uniformly distributed across the input space. It is precisely wrong when they aren't. The number you actually care about is the worst error across meaningful slices of the data:
where is the partition of inputs into subgroups. Marginal collapses into a single bucket. Worst-subgroup refuses to.
The pattern we see, on every realistic retrieval workload, looks the same. Partition the test set by which signal family — lexical, dense, or learned — has the strongest relative score on each query. The lexical-dominant slice has a calibration curve that drifts systematically above the diagonal: the system is over-confident on those queries. The dense-dominant slice drifts below: the system is under-confident. The two errors are large, have opposite sign, and roughly cancel under aggregation. The marginal curve hugs the diagonal. is small. Subgroups are silently broken.
The magnitudes are not subtle. Across seven retrieval workloads we measure, every standard fusion method — reciprocal rank fusion, learned linear combination, post-hoc Platt scaling — has worst-subgroup between 1.5× and 7× larger than its marginal value. On a representative workload, the strongest single retriever's marginal is 0.094 while its worst-subgroup is 0.209. A team monitoring 0.094 is monitoring a number that is wrong about the actual reliability of the system by more than a factor of two, on the slice of queries where the failure compounds.
Why the failure mode bites in production specifically
Phyvant runs retrieval-augmented back-office automation in production at large enterprises, including at one of the world's largest commodity traders, where the threshold gates real operator work rather than benchmark queries. A subgroup the aggregate calibration curve averages out of existence is not a research curiosity in that context; it is a process silently degrading on the operators we are supposed to be helping, on a slice of work the dashboard says is fine.
In a benchmark, a 7× subgroup gap is a curiosity. In production, it determines who gets a wrong answer. If the lexical-dominant subgroup is over-confident, queries in that subgroup are pushed across the threshold when they shouldn't be. The system grounds generations on retrievals the calibrated probability does not actually support. The generator does what it was asked to do — produce a fluent answer from the retrieved context — and produces a fluent answer from a wrong context. That is a hallucination, and it is concentrated in the subgroup the aggregate metric averaged out of existence.
In the other direction, an under-confident subgroup pushes queries below the threshold that should have been answered. The system abstains on questions it would have gotten right. The visible cost is lower coverage. The invisible cost is which queries lost coverage; if the dense-dominant slice happens to correlate with a particular customer segment, language, or document type, you are silently degrading service for that slice without anything in your monitoring telling you so.
Subgroup choice is not optional and not arbitrary
You cannot guarantee calibration on every conceivable subgroup family without paying for it. There is one family on which the failure mode is structural rather than incidental, and it is the one we use: signal-family dominance.
For each query, look at the standardised component scores and assign the query to whichever family — lexical (BM25-like), dense (embedding-based), or learned (cross-encoder) — has the strongest relative signal. Freeze this partition on the calibration split, do not recompute it per method, and treat worst-subgroup error against this partition as the quality metric.
This is the partition along which a fused predictor's component biases diverge. A score that linearly combines three signal families will, almost by construction, be miscalibrated on the slice where one signal is doing most of the work, because the calibration data does not contain enough of that slice to nail down the contribution of the dominant signal independently. Robustness checks against alternative partitions — query-length tertiles, fused-confidence tertiles — leave the conclusion unchanged. Signal-family dominance is the operative axis. Stratifying along anything else fails to expose the structural failure, so the fix doesn't bind.
What we do
Two stages, frozen partition, no exotic ingredients.
The base predictor is mundane: Platt-calibrate each component signal independently, then logistic-regress the calibrated logits onto the relevance label. This puts every signal on a probability scale and combines them into a single fused log-odds. Component-level calibration is a precondition for fusion at all — you can't add a raw cross-encoder margin to a raw BM25 score and expect the result to mean anything as a probability.
The second stage is where the subgroup discipline shows up. Within each signal-family-dominance stratum , fit a monotone calibration map on top of the base predictor's output:
The monotone fit preserves the parametric ranking, corrects per-stratum probability assignment, and returns more than a point estimate — it comes with a finite-sample envelope around each calibrated prediction, which lets the abstention path reason about its own uncertainty rather than treating the score as a noiseless probability.
The whole pipeline runs in single-digit minutes on an A10 for the largest workload we evaluate. There is nothing computationally exotic about it. The work the method does is putting a separate, shape-restricted nonparametric correction on each stratum, rather than relying on a single global Platt or isotonic fit to be right everywhere. An ablation against alternative within-stratum calibrators (subgroup-Platt, subgroup-isotonic, free-form HKRR) isolates the operative piece: the per-stratum shape-restricted nonparametric fit is what does the work, not the stratification alone.
What we measure
Mean ± standard deviation over five query-level resplits, paired t-test at 0.05.
- Lowest worst-subgroup on every one of seven retrieval workloads.
- Reduction over the strongest single retriever spans 1.1× (statistical tie) to 8.5×; six of seven workloads are significant at p < 0.05.
- Against the strongest learned-fusion baseline with a subgroup-stratified Platt correction added on top: three wins at p < 0.05, four ties, no losses.
- Marginal ECE is essentially unchanged from the base predictor. The work happens on the subgroups the aggregate metric was averaging away — exactly where it should.
The wins against subgroup-stratified Platt show up on the workloads where within-stratum shape demands more flexibility than a two-parameter monotone form can express. On simpler within-stratum shapes, subgroup-Platt is sufficient and we tie.
What this changes downstream
Two consequences follow that we think are underweighted in the way calibration is usually motivated.
The first is selective answering. If the fused score is calibrated on every subgroup, then confidence-restricted answers are higher quality than full-coverage answers, on every slice, not just on average. This is the property that makes a confidence-gated abstention path a quality lever rather than a coverage knob you tune empirically.
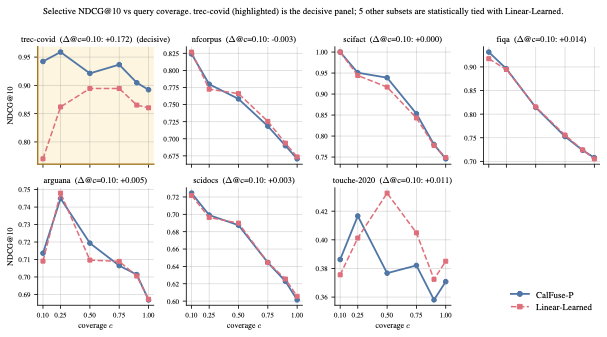
The figure shows the property concretely. Sort test queries by the system's confidence; report quality on the top c fraction. On the workload where the uncalibrated baseline's confidence ranking is structurally non-monotone in actual quality, our method's quality rises as coverage tightens while the baseline's quality falls — about a seventeen-point gap at coverage 0.10. On workloads where the uncalibrated ranking is already approximately quality-aligned, both rules ride the same curve and there's nothing to win. The win is exactly where the baseline was silently misranking confidence — also where the subgroup miscalibration was hiding.
The second is hallucination, measured end-to-end. On the queries the system does not refuse, calibration reduces the rate at which the generator produces wrong answers. The mechanism is not what you'd guess. The naive theory is that calibration sharpens the rank of the correct passage so the generator sees better context. We tested that directly — the rank of the first relevant passage barely moves across calibration methods. What changes is what the calibrated system retrieves alongside the positive: fewer high-similarity distractors at high confidence. The generator was not failing because the right thing wasn't in the context window. It was failing because the wrong thing was. The right things were excluded from context, not promoted within it.
Implication
The dashboard you build for retrieval quality should not be able to look healthy when a subgroup is silently failing. If yours can, the metric is the bug. Aggregate ECE is the wrong number to monitor. Signal-family dominance is the right axis to stratify on. Per-stratum monotone calibration is the cheapest fix that actually closes the gap on production data, and the operational wins compound through selective answering and a hallucination-reduction mechanism that has more to do with what gets excluded from the context window than with what gets promoted within it.
The diagnostic and the fix are both available off the shelf. The contribution worth internalising is smaller and less glamorous: stratify before you average, and the failure mode you have been silently shipping shows up.